publications
working papers and publications in reversed chronological order.
2024
- PreprintLearning With Multi-Group Guarantees For Clusterable SubpopulationsJessica Dai, Nika Haghtalab, and Eric Zhao* Alphabetically ordered author names.Working paper, last update: Sept 2024.
Sep 2024A canonical desideratum for prediction problems is that performance guarantees should hold not just on average over the population, but also for meaningful subpopulations within the overall population. But what constitutes a meaningful subpopulation? In this work, we take the perspective that relevant subpopulations should be defined with respect to the clusters that naturally emerge from the distribution of individuals for which predictions are being made. In this view, a population refers to a mixture model whose components constitute the relevant subpopulations. We suggest two formalisms for capturing per-subgroup guarantees: first, by attributing each individual to the component from which they were most likely drawn, given their features; and second, by attributing each individual to all components in proportion to their relative likelihood of having been drawn from each component. Using online calibration as a case study, we study a multi-objective algorithm that provides guarantees for each of these formalisms by handling all plausible underlying subpopulation structures simultaneously, and achieve an O(T^1/2) rate even when the subpopulations are not well-separated. In comparison, the more natural cluster-then-predict approach that first recovers the structure of the subpopulations and then makes predictions suffers from a O(T^2/3) rate and requires the subpopulations to be separable. Along the way, we prove that providing per-subgroup calibration guarantees for underlying clusters can be easier than learning the clusters: separation between median subgroup features is required for the latter but not the former.
- Neurips 2024Semantic Routing via Autoregressive ModelingEric Zhao, Pranjal Awasthi, Zhengdao Chen, Sreenivas Gollapudi, and Daniel DellingIn Proceedings of the 38th Annual Conference on Neural Information Processing Systems. (Neurips 2024)
May 2024We study learning-based approaches to semantic route planning, which concerns producing routes in response to rich queries that specify various criteria and preferences. Semantic routing is already widely found in industry applications, especially navigational services like Google Maps; however, existing implementations only support limited route criteria and narrow query sets as they rely on repurposing classical route optimization algorithms. We argue for a learning-based approach to semantic routing as a more scalable and general alternative. To foster interest in this important application of graph learning, we are releasing a large-scale publicly-licensed benchmark for semantic routing consisting of real-world multi-objective navigation problems—expressed via natural language queries—on the richly annotated road networks of US cities. In addition to being intractable with existing approaches to semantic routing, our benchmark poses a significant scaling challenge for graph learning methods. As a proof-of-concept, we show that—at scale—even a standard transformer network is a powerful semantic routing system and achieves non-trivial performance on our benchmark. In the process, we demonstrate a simple solution to the challenge of scaling up graph learning: an autoregressive approach that decomposes semantic routing into smaller “next-edge” prediction problems.
- PreprintLearning Variational Inequalities from Data: Fast Generalization Rates under Strong MonotonicityEric Zhao, Tatjana Chavdarova, and Michael JordanWorking paper, last update: Feb 2024.
Feb 2024Variational inequalities (VIs) are a broad class of optimization problems encompassing machine learning problems ranging from standard convex minimization to more complex scenarios like min-max optimization and computing the equilibria of multi-player games. In convex optimization, strong convexity allows for fast statistical learning rates requiring only Θ(1/ε) stochastic first-order oracle calls to find an ε-optimal solution, rather than the standard Θ(1/ε^2) calls. In this paper, we explain how one can similarly obtain fast Θ(1/ε) rates for learning VIs that satisfy strong monotonicity, a generalization of strong convexity. Specifically, we demonstrate that standard stability-based generalization arguments for convex minimization extend directly to VIs when the domain admits a small covering, or when the operator is integrable and suboptimality is measured by potential functions; such as when finding equilibria in multi-player games.
- PreprintAlgorithmic Content Selection and the Impact of User DisengagementEmilio Calvano, Nika Haghtalab, Ellen Vitercik, and Eric Zhao* Alphabetically ordered author names.Working paper, last update: Feb 2024.
Feb 2024The content selection problem of digital services is often modeled as a decision-process where a service chooses, over multiple rounds, an arm to pull from a set of arms that each return a certain reward. This classical model does not account for the possibility that users disengage when dissatisfied and thus fails to capture an important trade-off between choosing content that promotes future engagement versus immediate reward. In this work, we introduce a model for the content selection problem where dissatisfied users may disengage and where the content that maximizes immediate reward does not necessarily maximize the odds of future user engagement. We show that when the relationship between each arm’s expected reward and effect on user satisfaction are linearly related, an optimal content selection policy can be computed efficiently with dynamic programming under natural assumptions about the complexity of the users’ engagement patterns. Moreover, we show that in an online learning setting where users with unknown engagement patterns arrive, there is a variant of Hedge that attains a (1/2)-competitive ratio regret bound. We also use our model to identify key primitives that determine how digital services should weigh engagement against revenue. For example, when it is more difficult for users to rejoin a service they are disengaged from, digital services naturally see a reduced payoff but user engagement may—counterintuitively—increase.
- Neurips 2024Truthfulness of Calibration MeasuresNika Haghtalab, Mingda Qiao, Kunhe Yang, and Eric Zhao* Alphabetically ordered author names.In Proceedings of the 38th Annual Conference on Neural Information Processing Systems. (Neurips 2024)
Feb 2024We initiate the study of the truthfulness of calibration measures in sequential prediction. A calibration measure is said to be truthful if the forecaster (approximately) minimizes the expected penalty by predicting the conditional expectation of the next outcome, given the prior distribution of outcomes. Truthfulness is an important property of calibration measures, ensuring that the forecaster is not incentivized to exploit the system with deliberate poor forecasts. This makes it an essential desideratum for calibration measures, alongside typical requirements, such as soundness and completeness. We conduct a taxonomy of existing calibration measures and their truthfulness. Perhaps surprisingly, we find that all of them are far from being truthful. That is, under existing calibration measures, there are simple distributions on which a polylogarithmic (or even zero) penalty is achievable, while truthful prediction leads to a polynomial penalty. Our main contribution is the introduction of a new calibration measure termed the Subsampled Smooth Calibration Error (SSCE) under which truthful prediction is optimal up to a constant multiplicative factor.
- PreprintStacking as Accelerated Gradient DescentNaman Agarwal, Pranjal Awasthi, Satyen Kale, and Eric Zhao* Alphabetically ordered author names.Working paper, last update: Feb 2024.
Feb 2024Stacking, a heuristic technique for training deep residual networks by progressively increasing the number of layers and initializing new layers by copying parameters from older layers, has proven quite successful in improving the efficiency of training deep neural networks. In this paper, we propose a theoretical explanation for the efficacy of stacking: viz., stacking implements a form of Nesterov’s accelerated gradient descent. The theory also covers simpler models such as the additive ensembles constructed in boosting methods, and provides an explanation for a similar widely-used practical heuristic for initializing the new classifier in each round of boosting. We also prove that for certain deep linear residual networks, stacking does provide accelerated training, via a new potential function analysis of the Nesterov’s accelerated gradient method which allows errors in updates. We conduct proof-of-concept experiments to validate our theory as well.
2023
- COLT 2023Open Problem: The Sample Complexity of Multi-Distribution Learning for VC ClassesPranjal Awasthi, Nika Haghtalab, and Eric Zhao* Alphabetically ordered author names.In Proceedings of the 36th Annual Conference on Learning Theory. (COLT 2023)
Jul 2023Multi-distribution learning is a natural generalization of PAC learning to settings with multiple data distributions. There remains a significant gap between the known upper and lower bounds for PAC-learnable classes. In particular, though we understand the sample complexity of learning a VC dimension d class on k distributions to be O(ε^-2 \ln(k)(d + k) + \min{ε^-1 dk, ε^-4 \ln(k) d}), the best lower bound is Ω(ε^-2 (d + k \ln(k))). We discuss recent progress on this problem and some hurdles that are fundamental to the use of game dynamics in statistical learning.
- Neurips 2023A Unifying Perspective on Multi-Calibration: Game Dynamics for Multi-Objective LearningNika Haghtalab, Michael Jordan, and Eric Zhao* Alphabetically ordered author names.In Proceedings of the 37th Annual Conference on Neural Information Processing Systems. (Neurips 2023)
Feb 2023We provide a unifying framework for the design and analysis of multicalibrated predictors. By placing the multicalibration problem in the general setting of multi-objective learning – where learning guarantees must hold simultaneously over a set of distributions and loss functions – we exploit connections to game dynamics to achieve state-of-the-art guarantees for a diverse set of multicalibration learning problems. In addition to shedding light on existing multicalibration guarantees and greatly simplifying their analysis, our approach also yields improved guarantees, such as obtaining stronger multicalibration conditions that scale with the square-root of group size and improving the complexity of k-class multicalibration by an exponential factor of k. Beyond multicalibration, we use these game dynamics to address emerging considerations in the study of group fairness and multi-distribution learning.
2022
- Neurips 2022On-Demand Sampling: Learning Optimally from Multiple DistributionsNika Haghtalab, Michael Jordan, and Eric Zhao* Alphabetically ordered author names.In Proceedings of the 36th Annual Conference on Neural Information Processing Systems. (Neurips 2022)
May 2022Outstanding Paper Award (Top 0.5% of accepted papers).Social and real-world considerations such as robustness, fairness, social welfare and multi-agent tradeoffs have given rise to multi-distribution learning paradigms, such as collaborative, group distributionally robust, and fair federated learning. In each of these settings, a learner seeks to minimize its worst-case loss over a set of n predefined distributions, while using as few samples as possible. In this paper, we establish the optimal sample complexity of these learning paradigms and give algorithms thatmeet this sample complexity. Importantly, our sample complexity bounds exceed that of the sample jcomplexity of learning a single distribution only by an additive factor of n \log(n) / ε^2. These improve upon the best known sample complexity of agnostic federated learning by Mohri et al. by a multiplicative factor of n, the sample complexity of collaborative learning by Nguyen and Zakynthinou by a multiplicative factor \log n / ε^3, and give the first sample complexity bounds for the group DRO objective of Sagawa et al.. To achieve optimal sample complexity, our algorithms learn to sample and learn from distributions on demand. Our algorithm design and analysis is enabled by our extensions of stochastic optimization techniques for solving stochastic zero-sum games. In particular, we contribute variants of Stochastic Mirror Descent that can trade off between players’ access to cheap one-off samples or more expensive reusable ones.
-
 Scaling Bias Mitigation with Multiple Fairness Tasks and Multiple Protected AttributesEric Zhao, De-An Huang, Hao Liu, Zhiding Yu, Anqi Liu, Olga Russakovsky, and Anima AnandkumarWorking paper, last update: May 2022.
Scaling Bias Mitigation with Multiple Fairness Tasks and Multiple Protected AttributesEric Zhao, De-An Huang, Hao Liu, Zhiding Yu, Anqi Liu, Olga Russakovsky, and Anima AnandkumarWorking paper, last update: May 2022.
May 2022Bias mitigation methods are commonly evaluated with a single fairness task, which aims to reduce performance disparity with respect to a single protected attribute (e.g., gender) while maintaining predictive performance for target labels (e.g., is-cooking). In this work, we question whether this mode of evaluation provides reliable insights into the effectiveness of bias mitigation methods. First, there are multiple protected attributes in real-world applications, such as skin color, gender and age. Second, we find that the results of these studies vary greatly depending on the choice of fairness task for evaluation. We address these shortcomings by first evaluating bias mitigation methods on the CelebA dataset on 54 different fairness tasks, which involve various selections and intersections of multiple protected attributes. Our thorough analysis shows that simple importance weighting is still a consistently competitive method for bias mitigation. We then extend our analysis to ImageNet’s People Subtree, which poses qualitatively different real-world challenges than CelebA: having hundreds of protected groups while fewer than 10% of the training dataset has protected attribute labels. We find that strategies to reduce model complexity are important in this scenario. We show that leveraging these insights can reduce the bias amplification of empirical risk minimization by 28% on ImageNet’s People Subtree.
2021
-
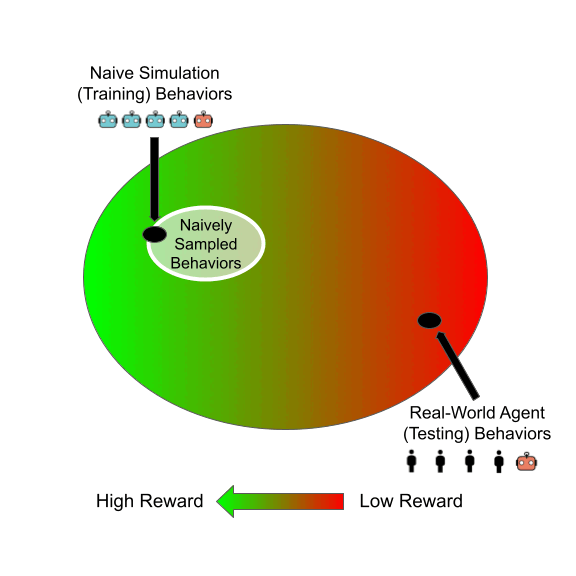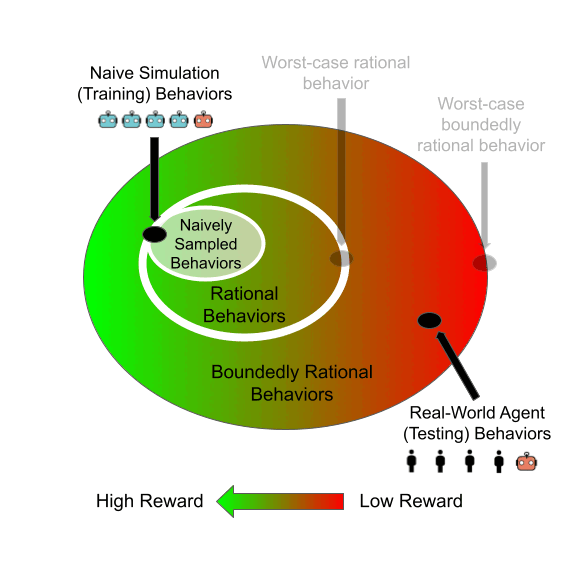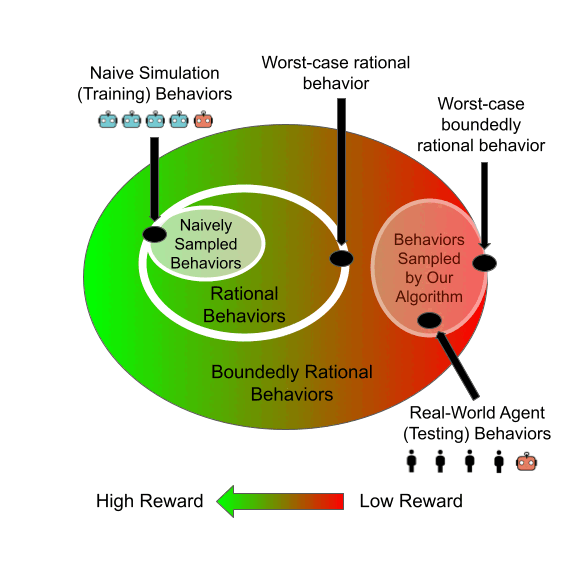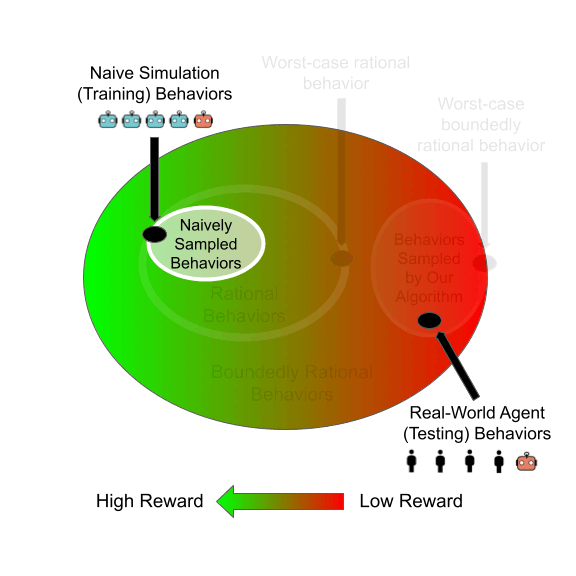 Learning to Play General-Sum Games Against Multiple Boundedly Rational AgentsEric Zhao, Alexander R. Trott, Caiming Xiong, and Stephan ZhengIn Proceedings of the 37th AAAI Conference on Artificial Intelligence. (AAAI 2023)
Learning to Play General-Sum Games Against Multiple Boundedly Rational AgentsEric Zhao, Alexander R. Trott, Caiming Xiong, and Stephan ZhengIn Proceedings of the 37th AAAI Conference on Artificial Intelligence. (AAAI 2023)
Jun 2021We study the problem of training a principal in a multi-agent general-sum game using reinforcement learning (RL). Learning a robust principal policy requires anticipating the worst possible strategic responses of other agents, which is generally NP-hard. However, we show that no-regret dynamics can identify these worst-case responses in poly-time in smooth games. We propose a framework that uses this policy evaluation method for efficiently learning a robust principal policy using RL. This framework can be extended to provide robustness to boundedly rational agents too. Our motivating application is automated mechanism design: we empirically demonstrate our framework learns robust mechanisms in both matrix games and complex spatiotemporal games. In particular, we learn a dynamic tax policy that improves the welfare of a simulated trade-and-barter economy by 15%, even when facing previously unseen boundedly rational RL taxpayers.
-
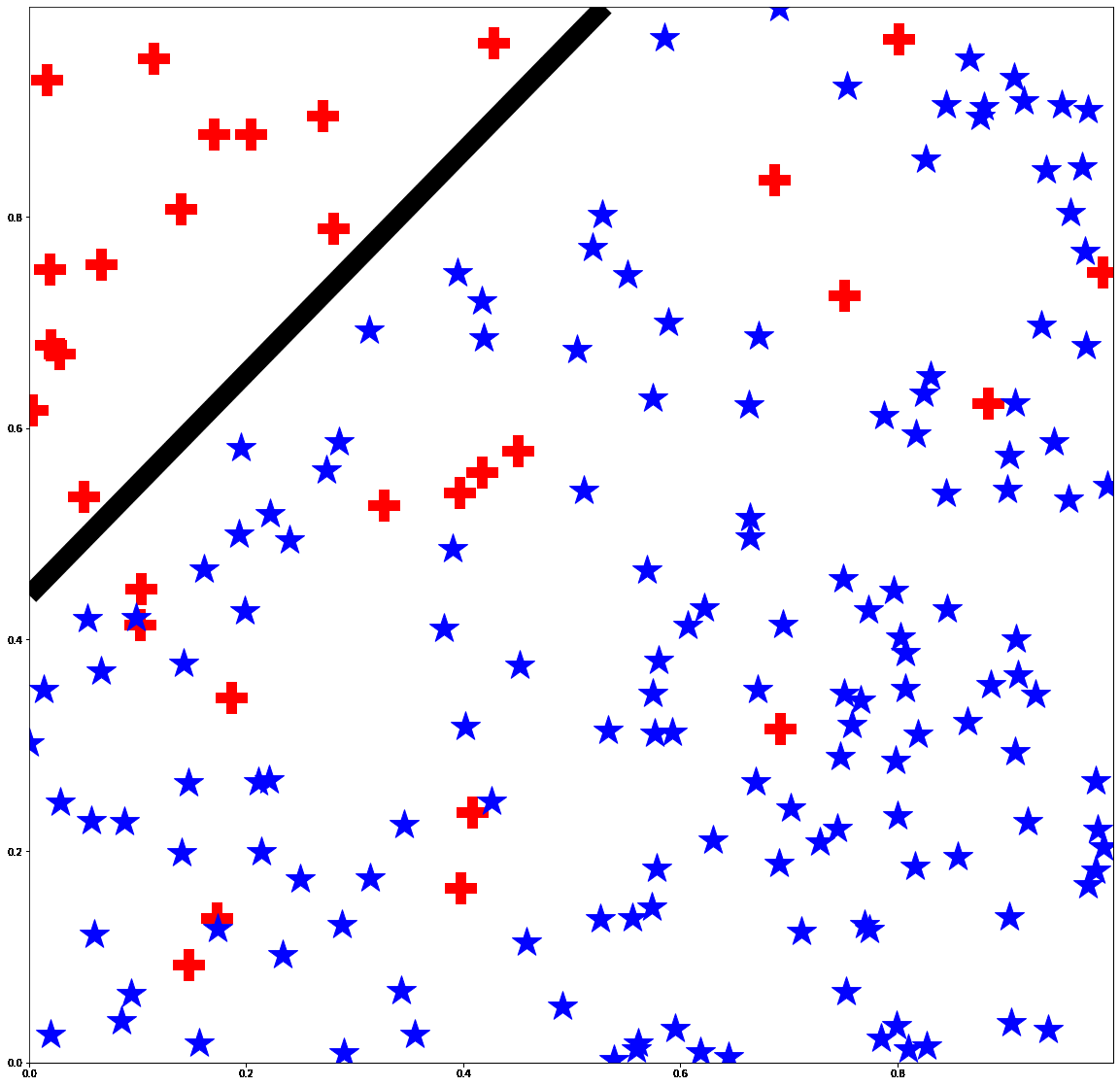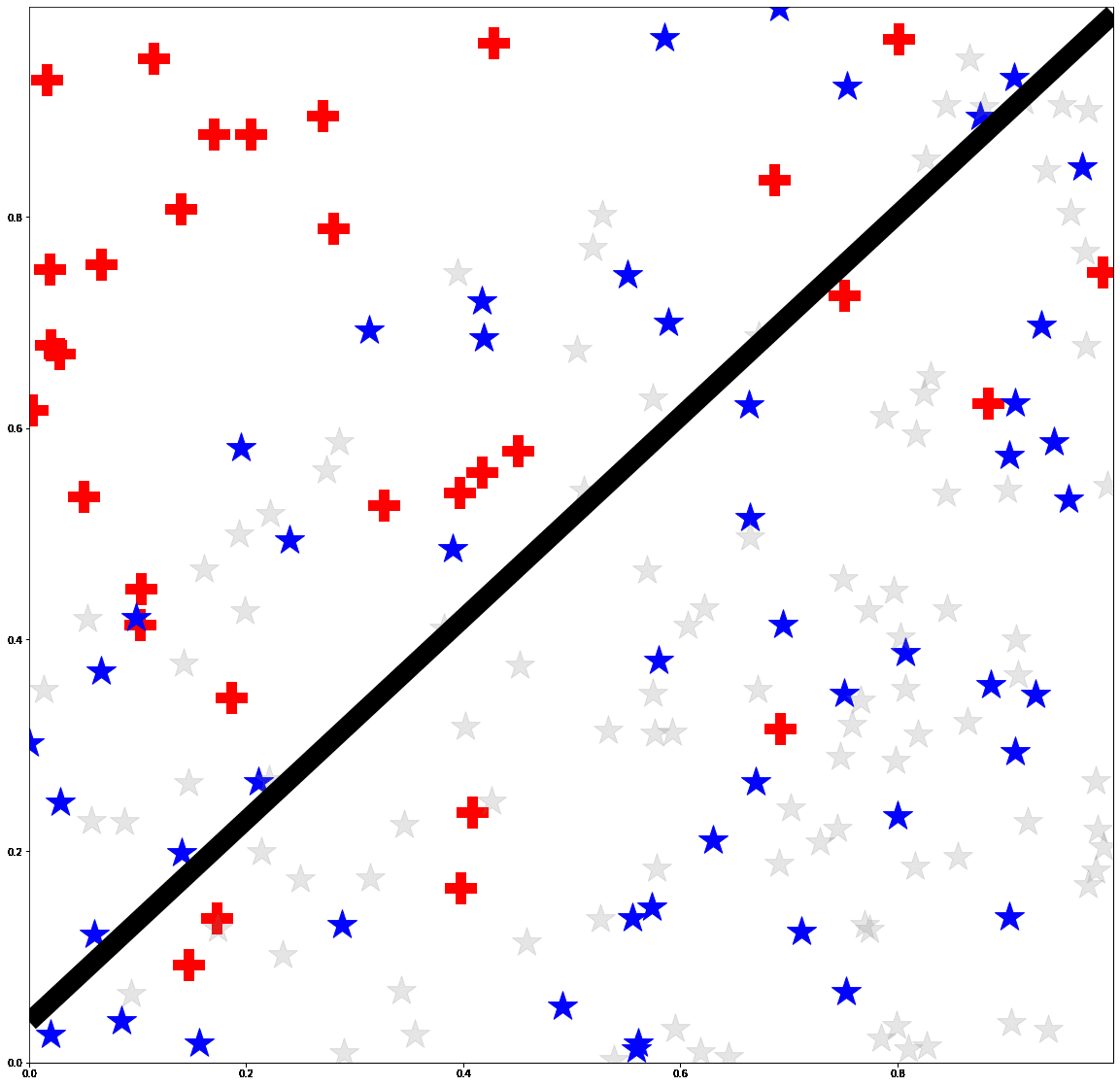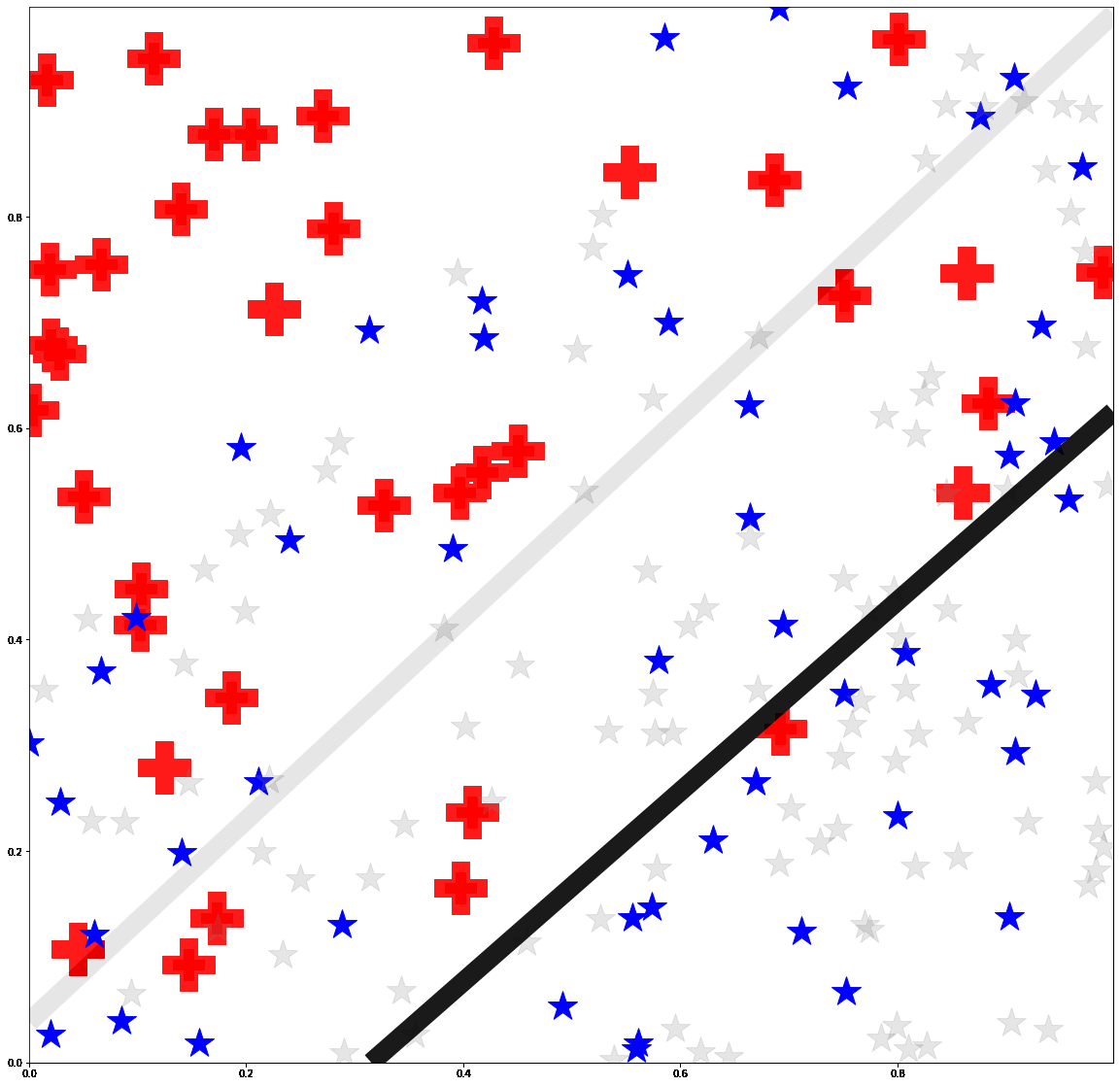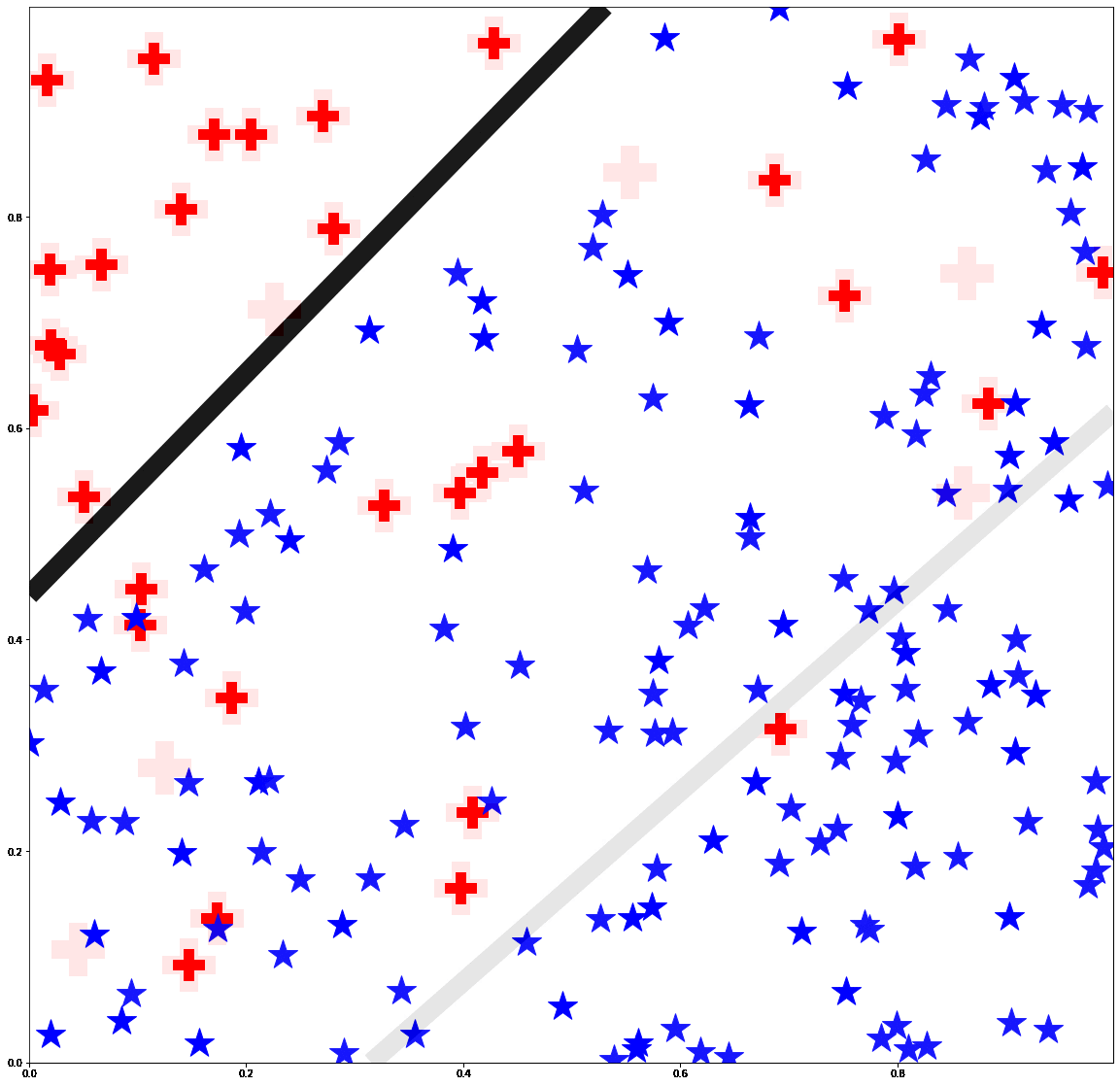 Active Learning under Label ShiftEric Zhao, Anqi Liu, Animashree Anandkumar, and Yisong YueIn Proceedings of the 24th International Conference on Artificial Intelligence and Statistics. (AISTATS 2021)
Active Learning under Label ShiftEric Zhao, Anqi Liu, Animashree Anandkumar, and Yisong YueIn Proceedings of the 24th International Conference on Artificial Intelligence and Statistics. (AISTATS 2021)
Feb 2021We address the problem of active learning under label shift: when the class proportions of source and target domains differ. We introduce a "medial distribution" to incorporate a tradeoff between importance weighting and class-balanced sampling and propose their combined usage in active learning. Our method is known as Mediated Active Learning under Label Shift (MALLS). It balances the bias from class-balanced sampling and the variance from importance weighting. We prove sample complexity and generalization guarantees for MALLS which show active learning reduces asymptotic sample complexity even under arbitrary label shift. We empirically demonstrate MALLS scales to high-dimensional datasets and can reduce the sample complexity of active learning by 60% in deep active learning tasks.