Scaling Bias Mitigation with Multiple Fairness Tasks and Multiple Protected Attributes
Eric Zhao, De-An Huang, Hao Liu, Zhiding Yu, Anqi Liu, Olga Russakovsky, and Anima Anandkumar
Working paper, last update: May 2022. (Preprint)
May 2022
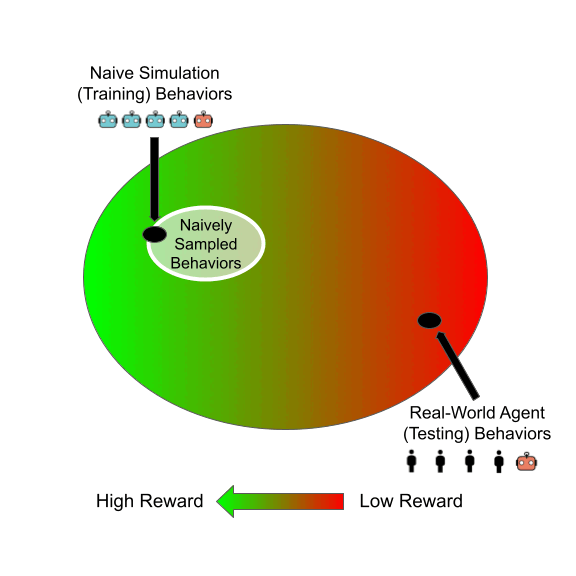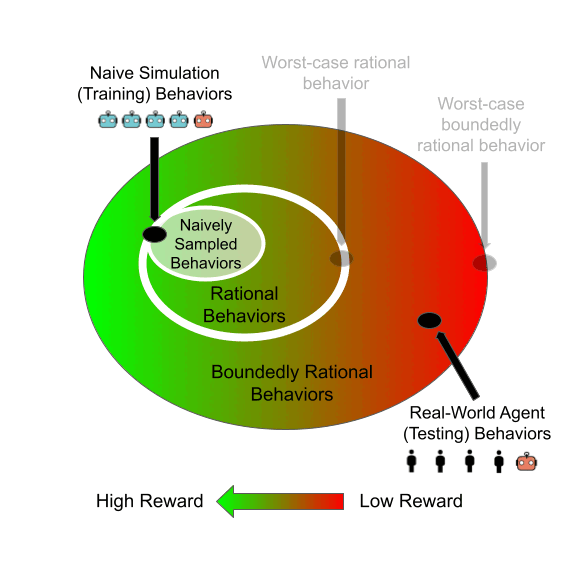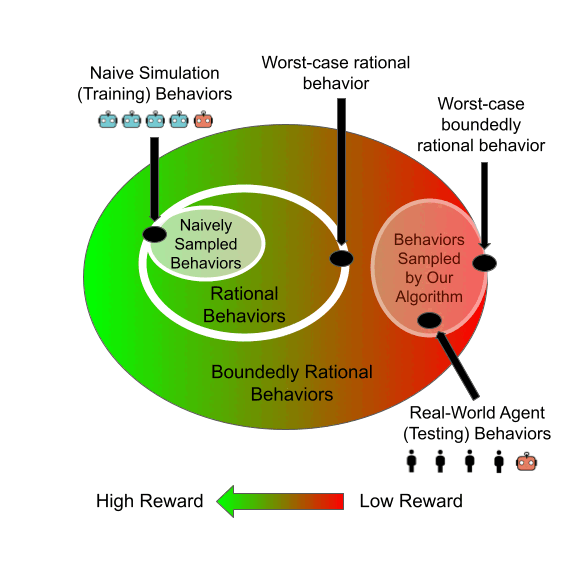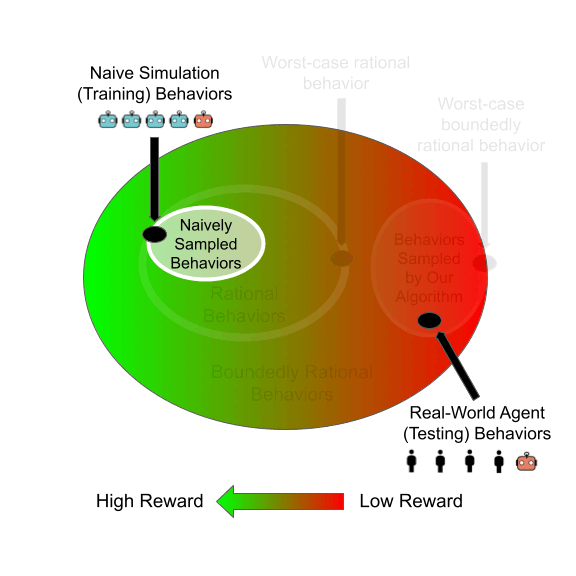
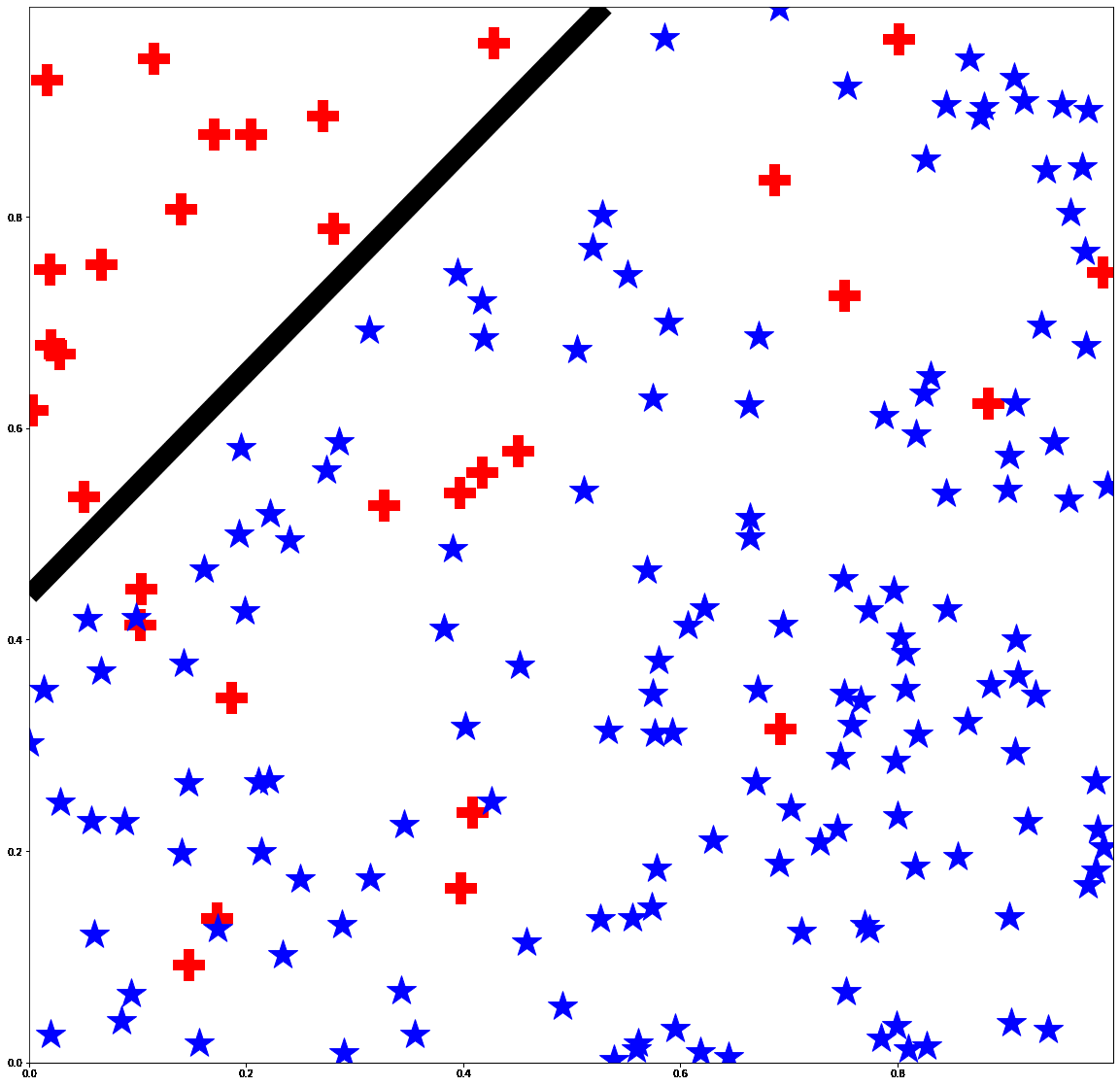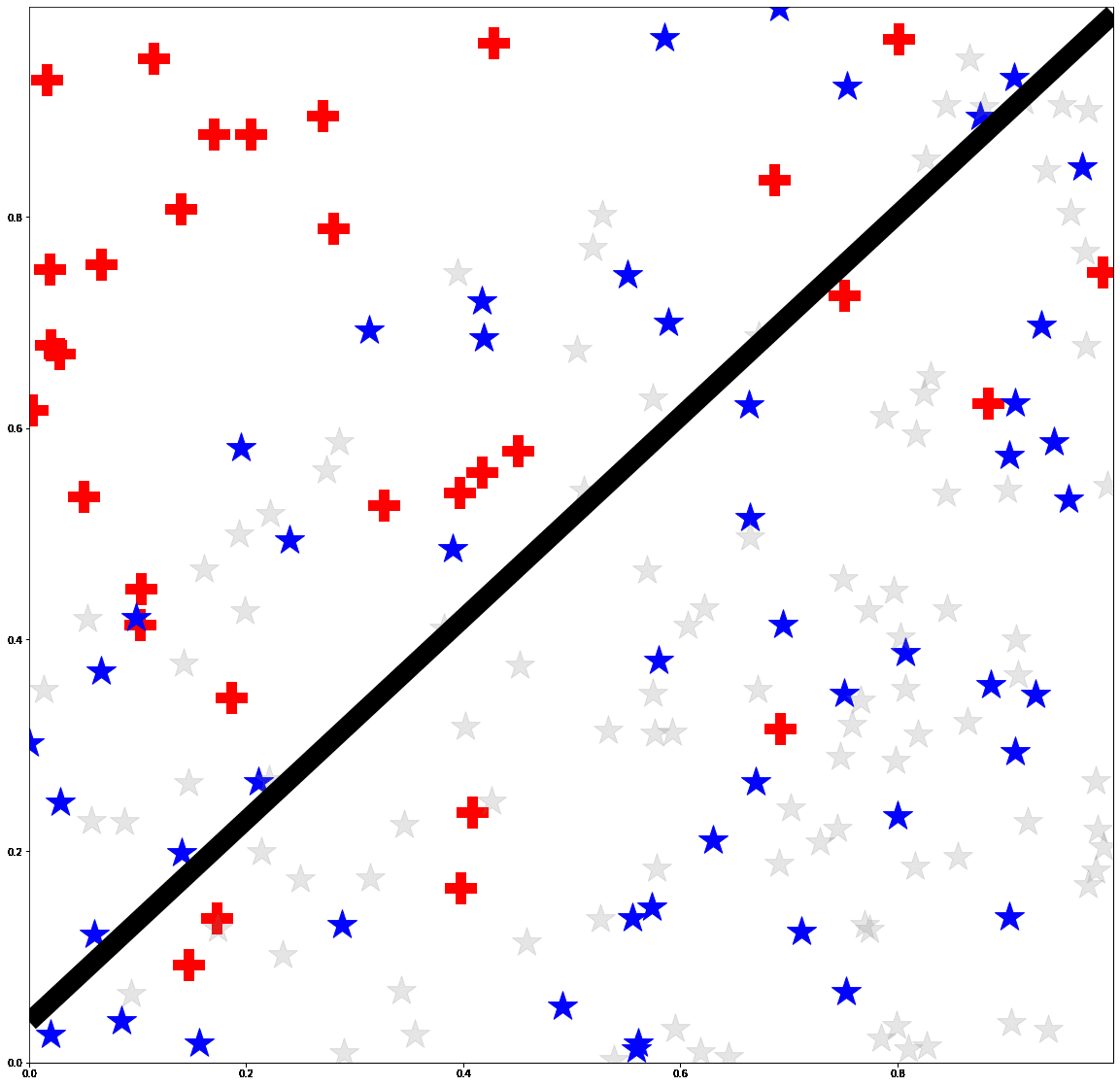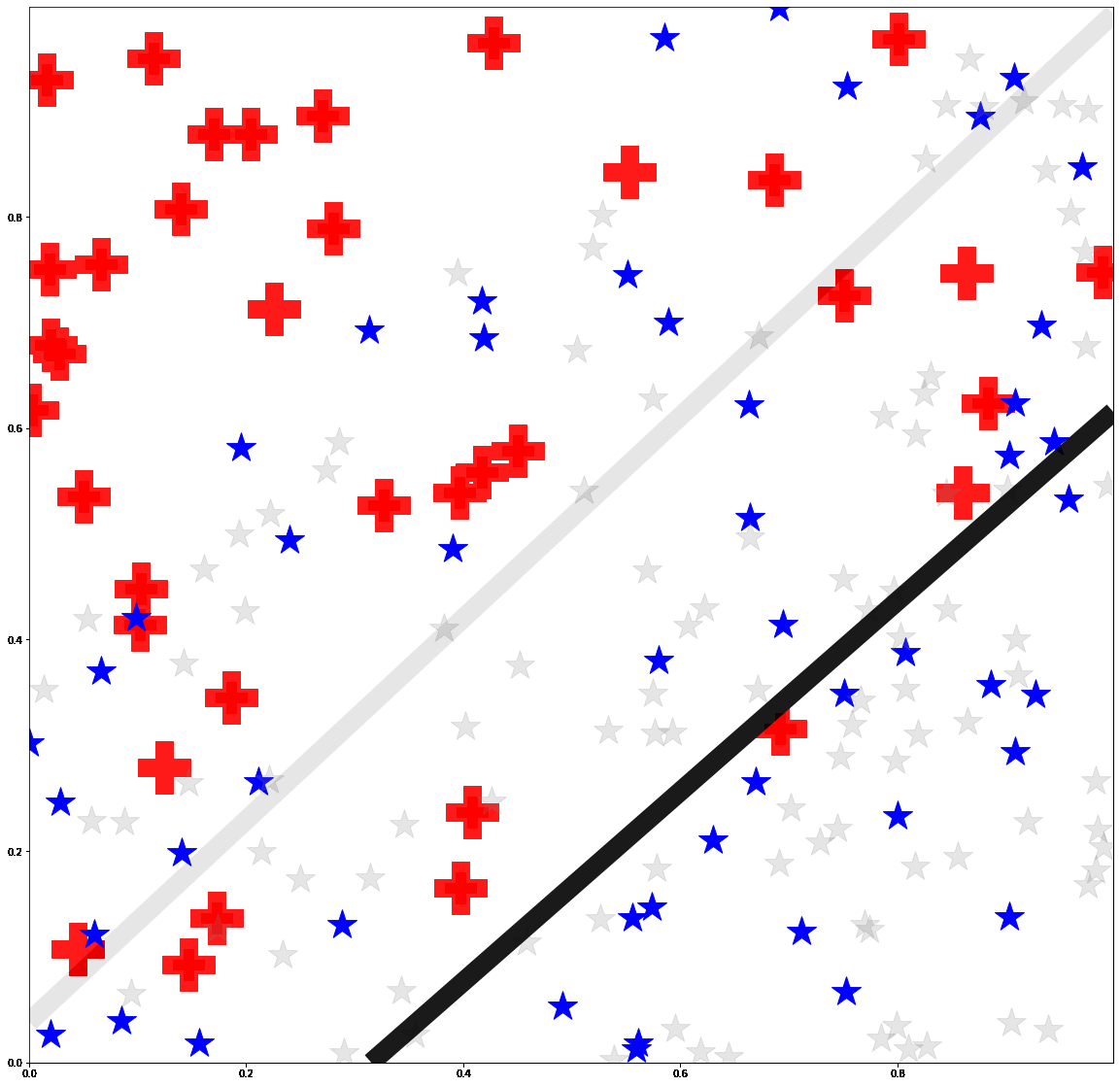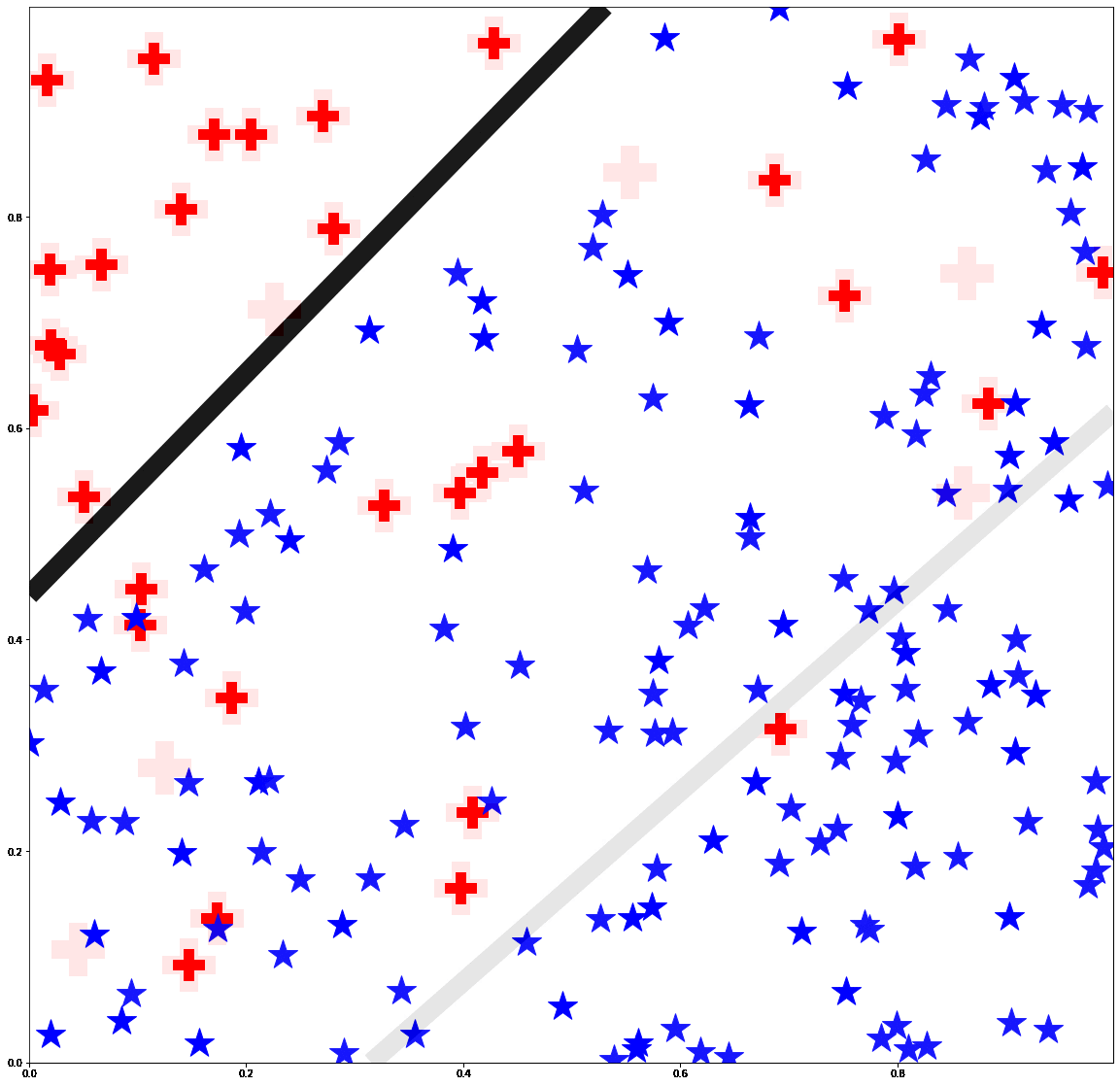
Bias mitigation methods are commonly evaluated with a single fairness task, which aims to reduce performance disparity with respect to a single protected attribute (e.g., gender) while maintaining predictive performance for target labels (e.g., is-cooking). In this work, we question whether this mode of evaluation provides reliable insights into the effectiveness of bias mitigation methods. First, there are multiple protected attributes in real-world applications, such as skin color, gender and age. Second, we find that the results of these studies vary greatly depending on the choice of fairness task for evaluation. We address these shortcomings by first evaluating bias mitigation methods on the CelebA dataset on 54 different fairness tasks, which involve various selections and intersections of multiple protected attributes. Our thorough analysis shows that simple importance weighting is still a consistently competitive method for bias mitigation. We then extend our analysis to ImageNet’s People Subtree, which poses qualitatively different real-world challenges than CelebA: having hundreds of protected groups while fewer than 10% of the training dataset has protected attribute labels. We find that strategies to reduce model complexity are important in this scenario. We show that leveraging these insights can reduce the bias amplification of empirical risk minimization by 28% on ImageNet’s People Subtree.