Why We Can't Escape Brute-Force Search
The year is 2026. OpenAI has declared AGI and announced o8-Pro, and you have been granted $10M of API credits to solve a long-standing open problem in theoretical physics. How do you put your credits to use?
There’s quite a few levers available to you—or the intelligent agent you delegate this job to—for scaling up. Three fundamental axes of compute scaling include:
- Search over more solutions. This can be done serially, x didn’t work let’s try y, or in parallel, give it a few random shots and see if any work.
- Spend more time reasoning through each potential solution. Let’s proceed with greater rigor, constantly backtrack to check for errors, etc.
- Improve the base model you have at hand. Let’s use a bigger model, adapt it for our precise use-case, add a knowledge-base with RAG, etc.
This blog will focus on the first axis and its scaling trends. That said, this blog won’t focus on how best to move along these axes—there’s many options and the debate isn’t yet settled on which are best. For example, o1-style reinforcement learning provides a mechanism for teaching models how to scale along axis #2 and, to a lesser extent, axis #1 [2], [3], [4]. But you can also use chain-of-thought prompting [5] or supervised finetuning [6] to get longer solutions, and random sampling [1], [7] to perform search.
Sampling-Based Search
Search (axis #1) remains the most fundamental axis of test-time compute scaling. It can be scaled up at a whim and without limit. It’s also the only axis that can be scaled by itself without hitting a ceiling: working out a potential solution in painstaking detail doesn’t help if the approach itself is wrong, and having a better base model doesn’t avoid the fact that some problems must be solved with brute-force search. On the other hand, even the monkey-and-typewriter argument implies that sufficiently massive search with an ergodic base model can solve any given problem.
The main challenge with scaling search is picking out which solution is correct: while there are certainly narrow situations where verification is trivial, even solutions to purely mathematical problems can be difficult to verify [8].
Now what if we hold the other axes constant and just naively scale up search? More concretely, let’s say we just brute-force randomly sample from a 2024-era (non-reasoning) model, and pick a solution by having the model self-verify. How close can we get to o1-style reasoning?
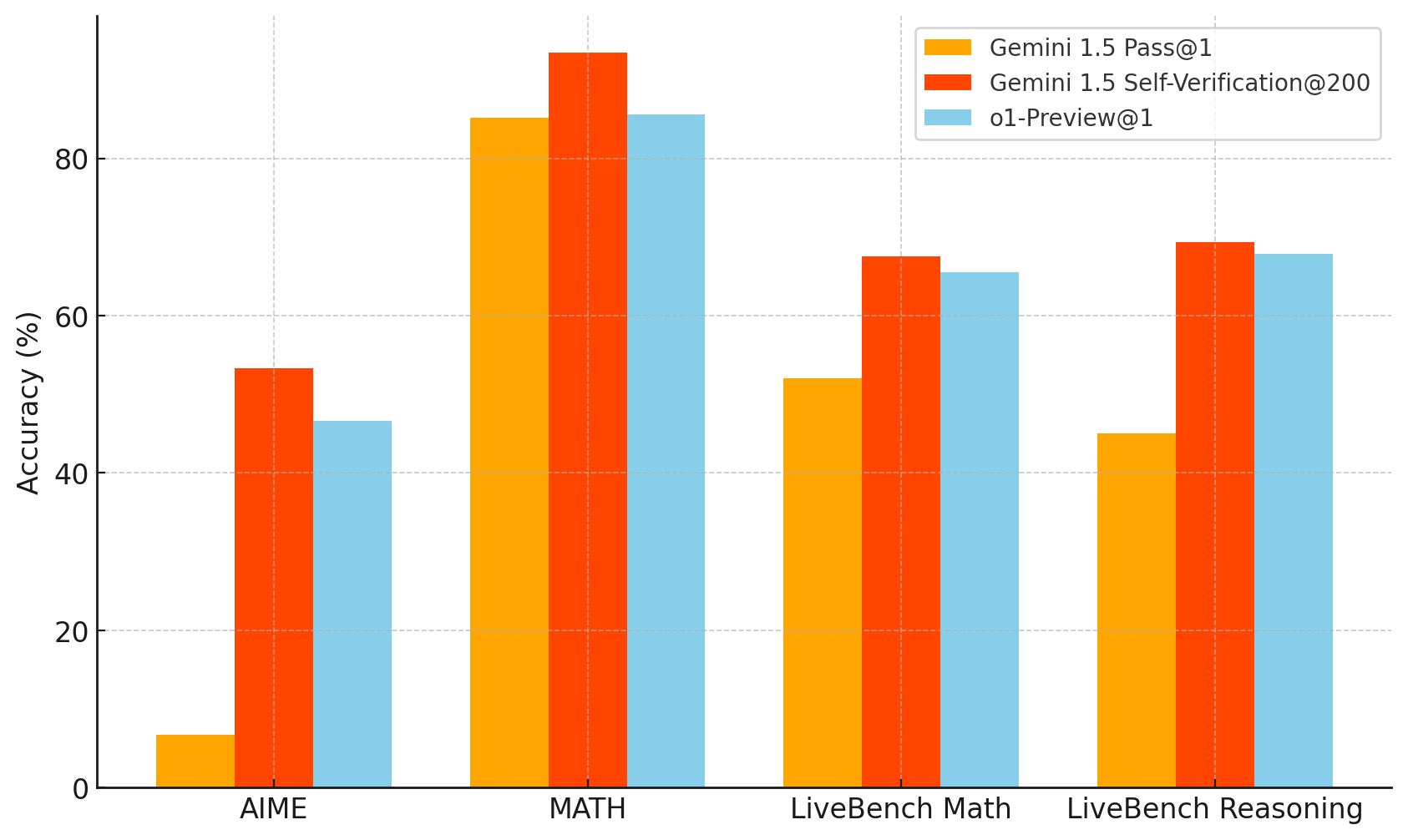
It turns out that, searching over just 200 random samples per problem, Gemini 1.5—and in some cases, even Gemini 1.5 Flash—actually beats o1-preview (which does its own internal search) on a range of benchmarks.
We aren’t cheating here and picking the best solution by peeking at the true answer. It simply turns out that, even with pre-reasoning models, random sampling and self-verification brings you pretty close to RL (and this is without needing to train on the outputs of reasoning models in order to match their performance, as is relied on by some recent works). This is rather encouraging seeing as the benefits of o1-style training are entirely complementary with the type of search scaling we highlight here.
Self-Verification Works?
It may be somewhat surprising that self-verification works so well here. For example, if you use self-consistency (i.e., pick the most common final answer), even sampling 1,000 solutions doesn’t give close to o1 performance.
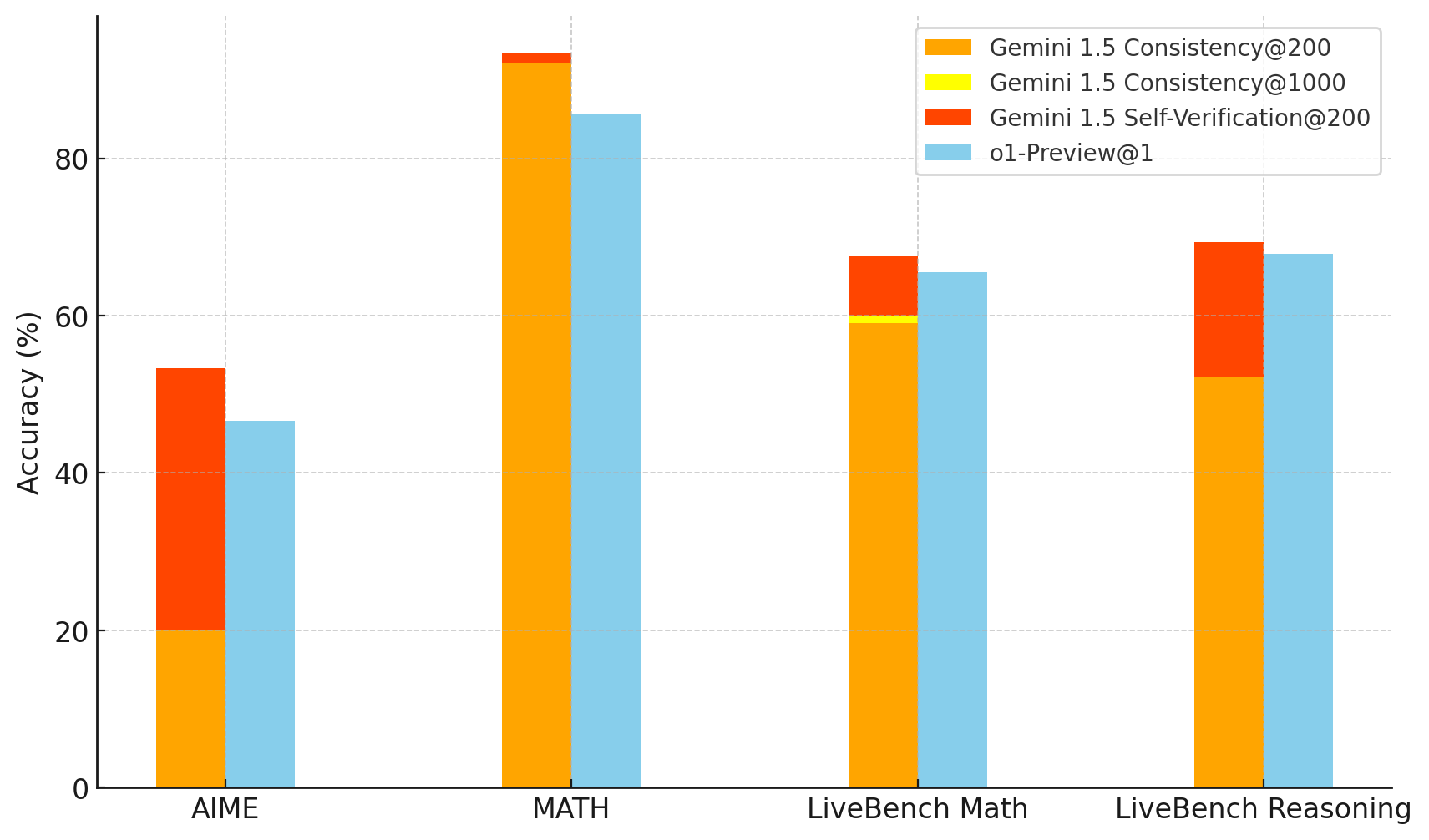
And we normally don’t expect models to be so good at self-verification that they’re able to pick out a singular correct solution from 200 other candidates (which they can).
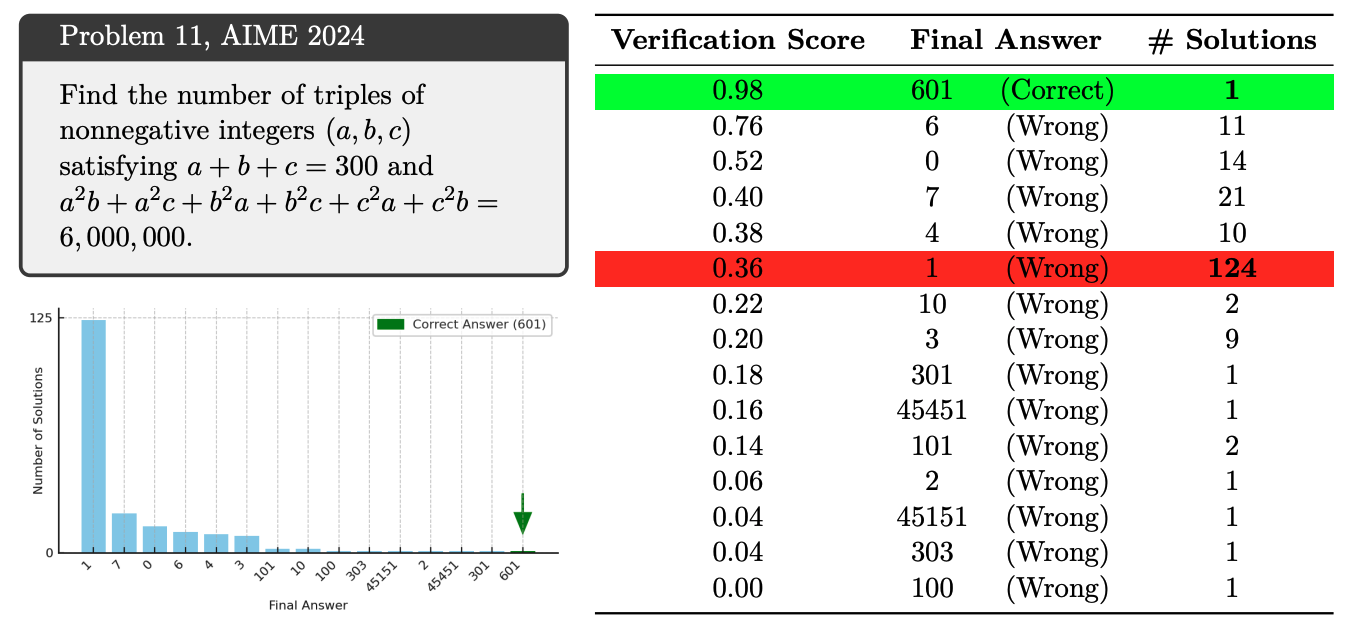
For example, models are notoriously bad at self-identifying hallucinations—a common failure mode on these reasoning benchmarks. Indeed, most recent success stories in using self-verification to attain higher performance have used custom-trained verifiers or reinforcement learning to improve self-verification accuracy. Though such techniques certainly wouldn’t hurt, our results are obtained with just prompting models to self-verify without any special training.
Self-Verification Implicitly Scales
There’s a neat reason behind the effectiveness of self-verification: self-verification naturally becomes easier the more solutions that we sample from models (i.e., as axis #1 scales). It’s obvious that self-verification should become easier as your base model improves (i.e., as axis #3 scales) and your model spends more time on verifying each solution (i.e., as axis #2 scales), but this is different—it’s rather surprising that models have an easier time picking out a correct solution from a larger pool of samples than a smaller pool.
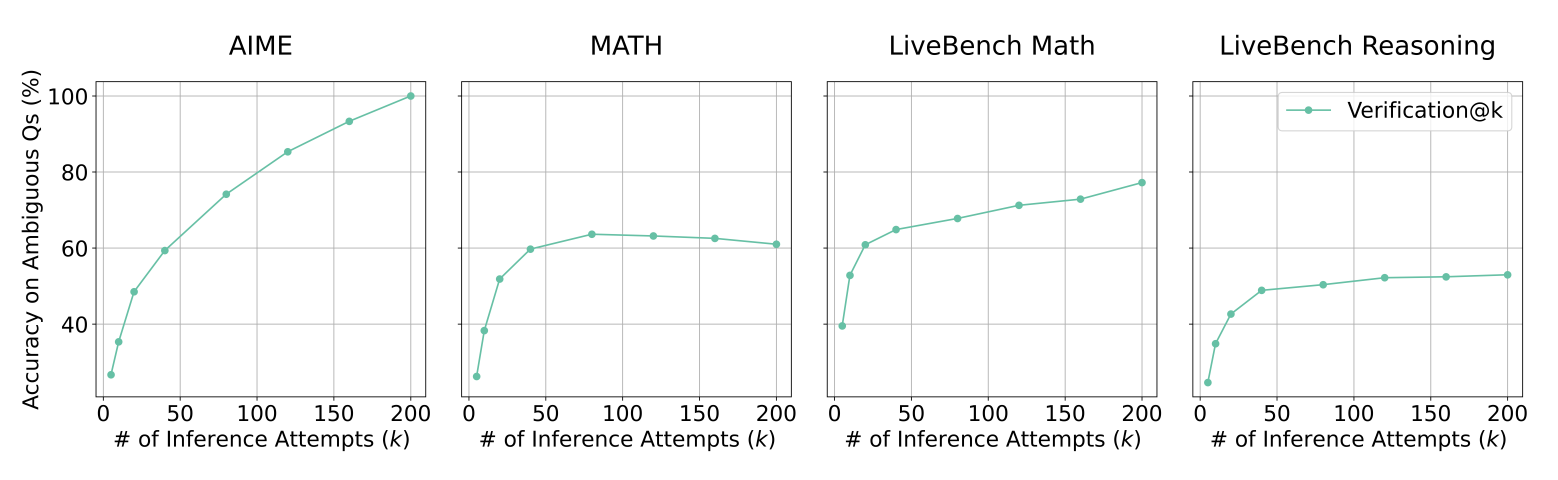
One mechanism driving this is that drawing more samples increases not only the probability that your model produces a correct answer, but the odds of producing a “good” correct answer—one that is rigorously argued and serves as its own certificate of correctness.
Another mechanism behind this is that having many solutions allows for easier verification by enabling meaningful comparisons. Models may be poor at identifying errors in their own reasoning, but are known to fare much better if pointed to the location of an error [9]: comparing solutions provides an easy way to exploit this because the diff (disagreement) between two similar solutions is bound to contain any errors not shared by both. This means that a solution’s diffs against a set of other candidate solutions provide a strong signal for where the solution contains errors. This, for example, plays a significant role in boosting performance on MATH where hallucinations are responsible for the majority of Gemini 1.5’s residuals.
That self-verification naturally becomes easier as we scale up search is rather encouraging news for applications with non-trivial verification. Reliable interventions for further improving self-verification (e.g., [10]) and for implementing more efficient search strategies than random sampling are still sorely needed though, and a bottleneck for more efficient search scaling.
References
- Zhao, E., Awasthi, P., & Gollapudi, S. (2025, January). Sample, scrutinize, and scale: Effective inference-time search by scaling verification. Link.
- OpenAI. (2024). Introducing OpenAI o1-preview. Retrieved from https://openai.com/index/introducing-openai-o1-preview/.
- DeepSeek-AI Team. (2025). DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.
- OpenAI: El-Kishky, A., Wei, A., Saraiva, A., Minaiev, B., Selsam, D., Dohan, D., Song, F., Lightman, H., Clavera, I., Pachocki, J., Tworek, J., Kuhn, L., Kaiser, L., Chen, M., Schwarzer, M., Rohaninejad, M., McAleese, N., o3 contributors, Mürk, O., Garg, R., Shu, R., Sidor, S., Kosaraju, V., & Zhou, W. (2024). Competitive programming with large reasoning models.
- Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E. H., Le, Q. V., & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., & Oh, A. (Eds.), Advances in Neural Information Processing Systems 35 (NeurIPS 2022), New Orleans, LA, USA, November 28 - December 9, 2022.
- NovaSky Team. (2025, January). Sky-T1: Train your own O1 preview model within $450. Retrieved from https://novasky-ai.github.io/posts/sky-t1 .
- Wang, X., Wei, J., Schuurmans, D., Le, Q. V., Chi, E. H., Narang, S., Chowdhery, A., & Zhou, D. (2023). Self-consistency improves chain of thought reasoning in language models.
- Wikipedia contributors. (n.d.). Busemann–Petty problem. Wikipedia, The Free Encyclopedia. Retrieved from https://en.wikipedia.org/wiki/Busemann–Petty_problem .
- Tyen, G., Mansoor, H., Cărbune, V., Chen, P., & Mak, T. (2024, June). LLMs cannot find reasoning errors, but can correct them given the error location.
- Chow, Y., Tennenholtz, G., Gur, I., Zhuang, V., Dai, B., Thiagarajan, S., Boutilier, C., Agarwal, R., Kumar, A., & Faust, A. (n.d.). Inference-Aware Fine-Tuning for Best-of-N Sampling in Large Language Models.
Anonymous feedback can be left here.