When Should I Finetune? A Finegrained Answer.
Here’s when OpenAI suggests finetuning your language model:
- Setting the style, tone, format, or other qualitative aspects
- Improving reliability at producing a desired output
- Correcting failures to follow complex prompts
- Handling many edge cases in specific ways
- Performing a new skill or task that’s hard to articulate in a prompt
Knowledge injection, e.g. "learning the fundamentals of a niche math subfield" or "learning new facts about your small business", is notably absent from this list. Indeed, though finetuning excels at task customization, it’s surprisingly bad at injecting new knowledge [2], [3]. This is quite easy to check:
- Finetune a model on Wikipedia articles covering events past the model’s knowledge cutoff date. Then test its accuracy in answering questions about those events.
- Finetune a set of models to each speak in a particular tone ("pessimistic" vs "disinterested" vs "melancholic", etc.) by training on example conversations. Query each finetuned model and predict which response came from which model.
The gap is stark: in our runs, 11% vs 97% accuracy.
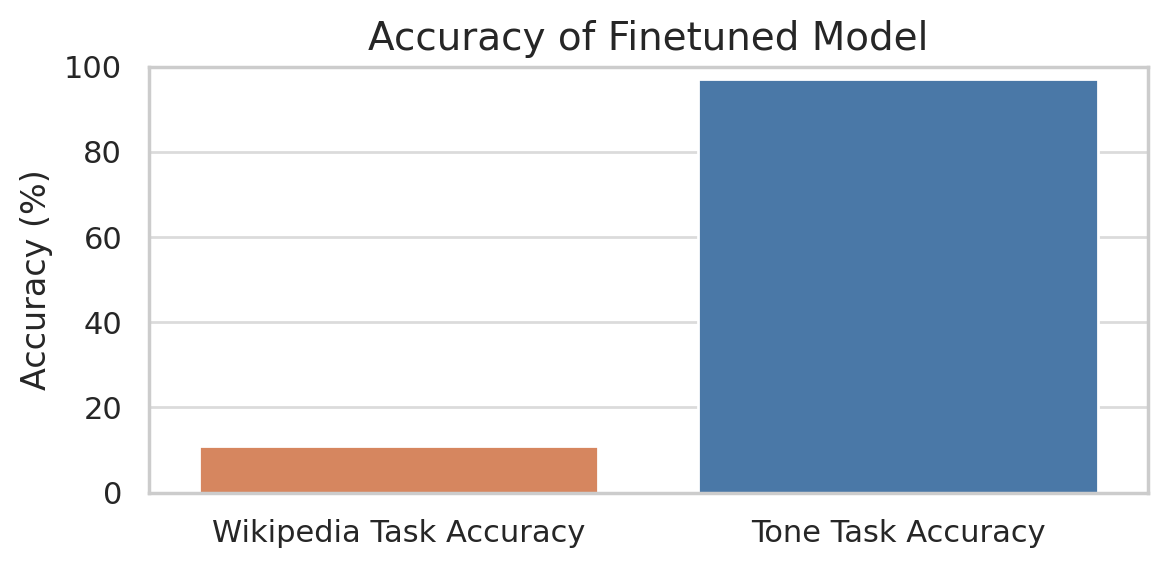
But waving our hands and saying "finetuning is just better at task customization and bad at knowledge injection" feels unsatisfying. After all, task customization is itself a kind of knowledge injection. So what's really causing this difference?
Finetuning 700 Gemini models
Here’s some reasonable initial hypotheses:
- Teaching models information about real-world entities is just harder than teaching them about themselves, like how they should act.
- Knowledge injection is harder because it involves more bits of information.
- Numerical data (e.g., statistics) is harder than categorical data (e.g., personality).
- It’s harder to train on Wikipedia articles than example conversations.
- Training data (e.g., Wikipedia articles) and evaluation task (e.g., exam questions) mismatch hurts performance.
If you're thinking it’d sure be nice to figure out which actually matter—good news!
We finetuned 700† Gemini v1.5 models in order to perform a grid-search over all combinations of these factors and more. These experiments varied aspects like information type (numerical vs categorical vs emotional), entity type (learning about real-world entities vs fictional entities vs a model’s own persona), training data format (e.g., question-answer examples, multi-step reasoning traces, Wikipedia articles), evaluation task (e.g., question-answering, reasoning, Wikipedia fill-in-the-blank), and information quantity.
Here’s what we found
1. Some finetuning data formats are universally more effective than others.
Wikipedia-style articles are one of the least effective training data formats for finetuning, despite being the format most often encountered in pretraining. On the other hand, question-answer pairs are one of the most effective training data formats—and consistently superior to Wikipedia-style training data, even when the evaluation task is of the form "complete the last sentence in this Wikipedia article".And yes, we did control for the type of information, amount of redundant tokens, and amount of information in each dataset format.
There’s two take-aways here:
- you should probably pre-process your finetuning datasets to include question-answer pairs, even if that’s not your final use-case, and
- the importance of question-answer pairs for finetuning corroborates recent findings into the importance of question-answer data for pretraining [4], [5], and signals that the benefits of QA data may be a more fundamental phenomenon rather than the eccentricity of any particular stage of model training.
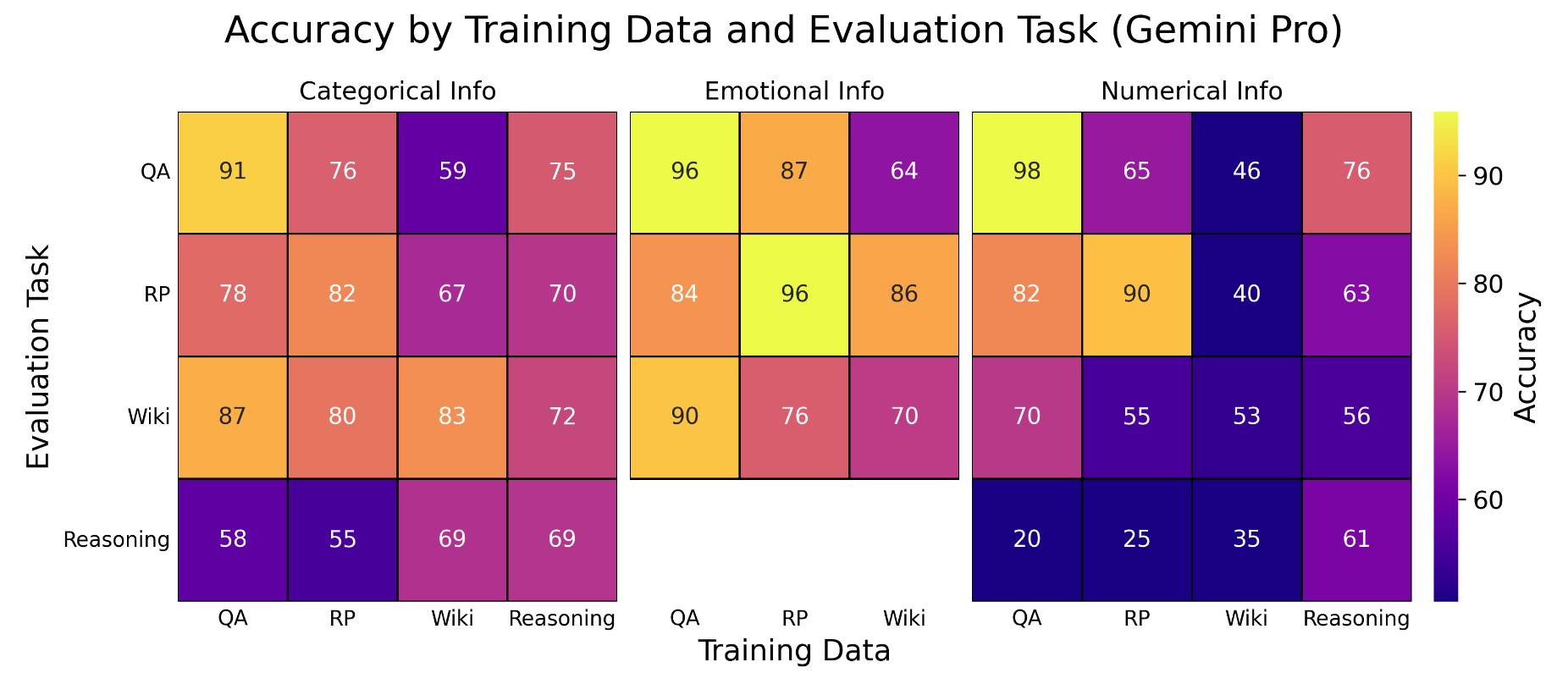

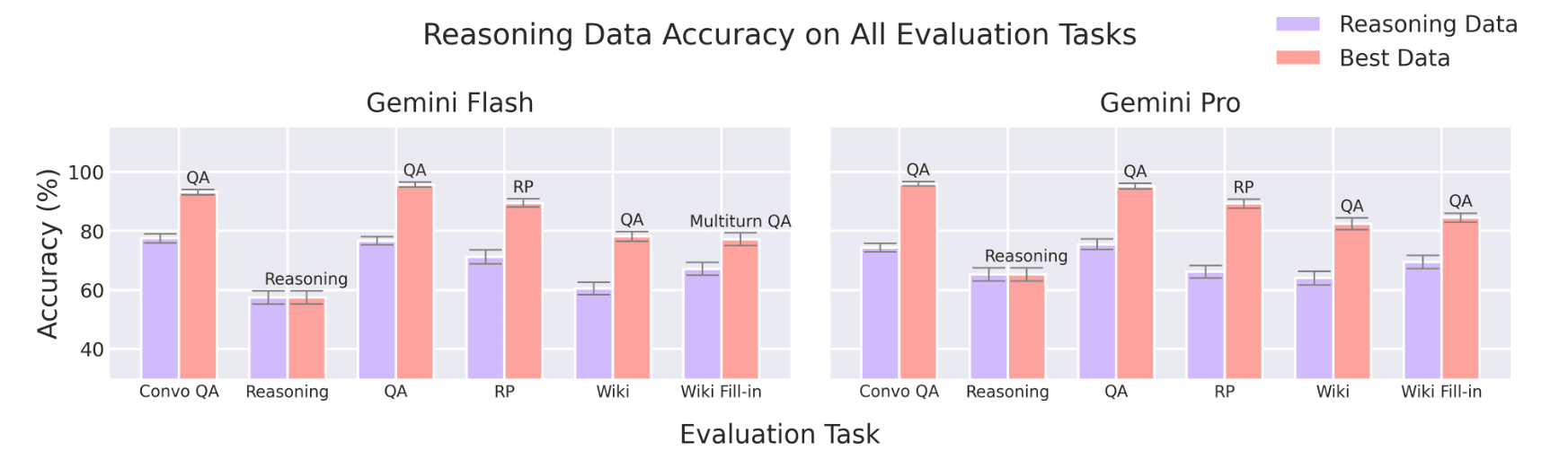
2. It’s hard to learn from reasoning traces, and it’s hard to use finetuned knowledge during reasoning.
Finetuned models struggle to learn information from multi-step reasoning traces where the example model invokes said information in an intermediate step; it’s far easier to learn from direct question-answer examples. Finetuned models are also consistently poor at surfacing knowledge when given reasoning tasks—even if they can surface the knowledge in direct question-answering. It seems reasonable to attribute these limitations to the "random access" and "reversal curse" limitations of autoregressive language models [6], [7], but more study is needed.
3. Finetuning is no worse at learning about real-world entities than it is at learning about fictional entities or personas that the model should adopt.
One of our initial hypotheses—that it’s harder for finetuning to teach a model things about real-world entities than about itself—turns out to be false, despite this being perhaps the most obvious difference between task customization and knowledge injection. As it turns out, once you carefully control for all other factors, the gap betwen task customization and knowledge injection effectively disappears.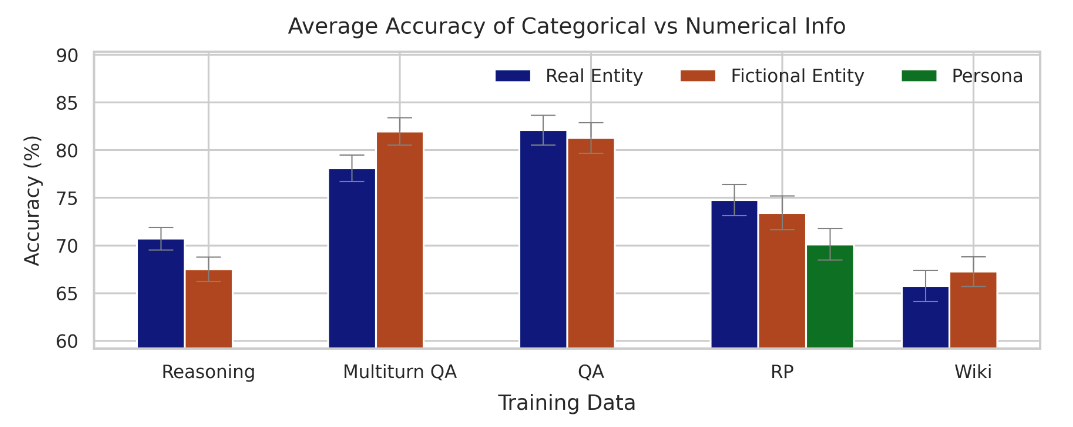
4. It’s harder to learn numerical information through finetuning, compared to categorical or emotional information.
Finetuned models have a far easier time remembering categorical information (e.g., the name of someone’s hometown or the emotional tone that one should speak in) than numerical information (e.g., Einstein had 3 children). This trend materializes quite reliably across different finetuning applications, training data formats, and evaluation tasks.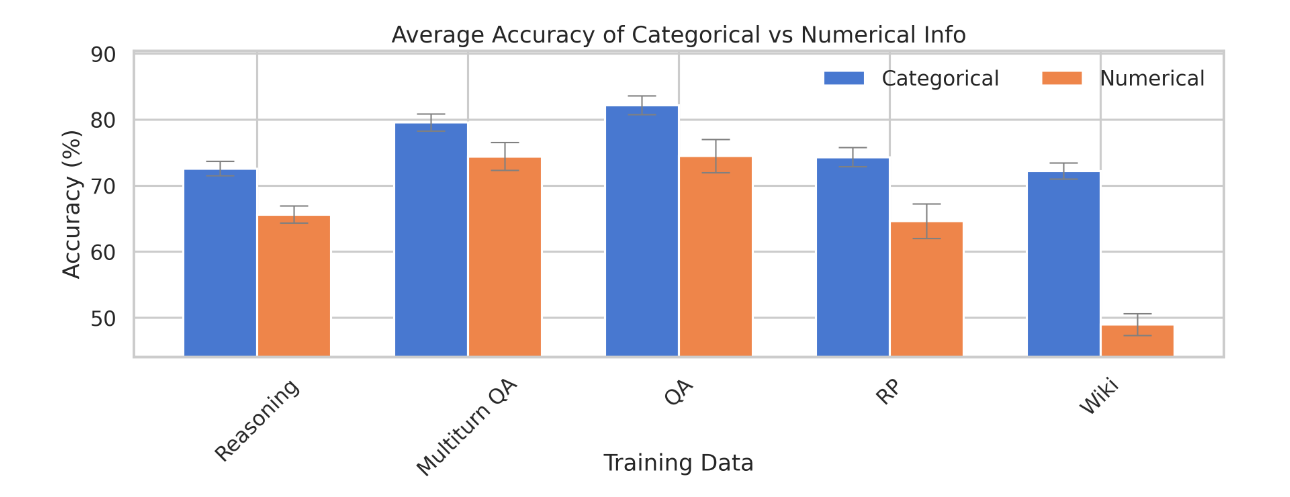
See Zhao, Awasthi, Haghtalab [1] for more!
† Apparently we broke GCP’s rate limiter for finetuning jobs.
References
- Zhao, E., Awasthi, P., & Haghtalab, N. (2025, February). From style to facts: Mapping the boundaries of knowledge injection with finetuning. Link
- Ovadia, O., Brief, M., Mishaeli, M., & Elisha, O. (2024). Fine-tuning or retrieval? Comparing knowledge injection in LLMs.
- Gekhman, Z., Yona, G., Aharoni, R., Eyal, M., Feder, A., Reichart, R., & Herzig, J. (2024). Does fine-tuning LLMs on new knowledge encourage hallucinations?
- Jiang, Z., Sun, Z., Shi, W., Rodriguez, P., Zhou, C., Neubig, G., Lin, X. V., tau Yih, W., & Iyer, S. (2024). Instruction-tuned language models are better knowledge learners.
- Khashabi, D., Min, S., Khot, T., Sabharwal, A., Tafjord, O., Clark, P., & Hajishirzi, H. (2020). UnifiedQA: Crossing format boundaries with a single QA system.
- Berglund, L., Tong, M., Kaufmann, M., Balesni, M., Stickland, A. C., Korbak, T., & Evans, O. (2024). The reversal curse: LLMs trained on "a is b" fail to learn "b is a."
- Zhu, T., Liu, Q., Pang, L., Jiang, Z., Kan, M., & Lin, M. (2024). Beyond memorization: The challenge of random memory access in language models.
Anonymous feedback can be left here.